[강의명]
패스트캠퍼스 SQL 100제 + 자격증 완성 온라인 완주반
[수강목록]
40. 집합 연산자와 서브쿼리 - 05. 서브쿼리란
41. 집합 연산자와 서브쿼리 - 06. ANY연산자
42. 집합 연산자와 서브쿼리 - 07. ALL연산자
43. 집합 연산자와 서브쿼리 - 08. EXISTS연산자
[강의내용]
40. 집합 연산자와 서브쿼리 - 05. 서브쿼리란
서브쿼리는 하나의 SQL문 안에 포함되어 있는 또 다른 SQL문을 말한다.

[특징]
서브쿼리를 괄호로 감싸서 사용한다
서브쿼리는 메인쿼리의 컬럼을 자유롭게 사용할 수 있다 (메인쿼리는 불가)
서브쿼리에서는 ORDER BY를 사용하지 못한다. ORDER BY절은 SELECT에서 오직 1개만 올 수 있기 때문에
ORDER BY절은 메인쿼리의 마지막 문장에 위치해야 한다.
SELECT절, FROM절, WHERE절, HAVING절, ORDER BY절 에서 사용 가능하다.
서브쿼리에는 3종류가 있다.
1) 중첩 서브쿼리: WHERE절에 존재하는 서브쿼리
2) 인라인 뷰: FROM절에 존재하는 서브쿼리
3) 스칼라 서브쿼리: SELECT절에 존재하는 서브쿼리
[실습1]RENTAL_RATE의 평균을 구해본다.
SELECT AVG(RENTAL_RATE)
FROM FILM;

전체 RENTAL_RATE에서 평균(2.98)보다 큰 집합만 추출하려고 한다.
SELECT FILM_ID, TITLE, RENTAL_RATE
FROM FILM
WHERE RENTAL_RATE > 2.98;
평균인 2.98 값을 직접 입력해줘야 하는 불편함이 있다.
위 2개의 SQL을 결합하여 같은 결과가 나오게 해보자
[실습2] WHERE절에 서브쿼리 사용
중첩 서브쿼리를 사용해본다
SELECT FILM_ID, TITLE, RENTAL_RATE
FROM FILM
WHERE RENTAL_RATE > (
SELECT AVG (RENTAL_RATE)
FROM FILM
);

[실습3] FROM절에 서브쿼리 사용
인라인 뷰를 사용해본다
SELECT A.FILM_ID, A.TITLE, A.RENTAL_RATE
FROM FILM A, (
SELECT AVG(RENTAL_RATE) AS AVG_RENTAL_RATE
FROM FILM
) B
WHERE A.RENTAL_RATE > B.AVG_RENTAL_RATE;

[실습4] SELECT절에 서브쿼리 사용
스칼라 서브쿼리를 사용해본다
SELECT A.FILM_ID, A.TITLE, A.RENTAL_RATE
FROM (SELECT A.FILM_ID, A.TITLE, A.RENTAL_RATE, (
SELECT AVG(L.RENTAL_RATE)
FROM FILM L
) AS AVG_RENTAL_RATE
FROM FILM A) A
WHERE A.RENTAL_RATE > A.AVG_RENTAL_RATE;
코드가 복잡해 이번 문제에는 어울리지 않는 느낌이다.

3가지 모두 결과는 동일하다.
어떤게 빠른지는 알 수 없다.
옵티마이저가 성능 좋게 바꿔서 처리해서 결과 돌려주기 때문이다.
41. 집합 연산자와 서브쿼리 - 06. ANY연산자
ANY 연산자는 값을 서브쿼리에 의해 반환된 값 집합과 비교하고,
서브쿼리의 값이 어떠한 값이라도 만족하면 조건이 성립된다.
[실습]
카테고리(Action, Drama,..)별 상영시간이 가장 긴 영화의 상영시간을 구해본다
SELECT MAX(LENGTH)
FROM FILM A, FILM_CATEGORY B
WHERE A.FILM_ID = B.FILM_ID
GROUP BY B.CATEGORY_ID;
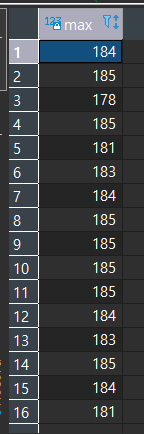
이 결과집합보다 상영시간이 같거나 큰 영화들의 제목, 상영시간을 구한다.
SELECT TITLE, LENGTH
FROM FILM
WHERE LENGTH >= ANY (
SELECT MAX(LENGTH)
FROM FILM A, FILM_CATEGORY B
WHERE A.FILM_ID = B.FILM_ID
GROUP BY B.CATEGORY_ID
);
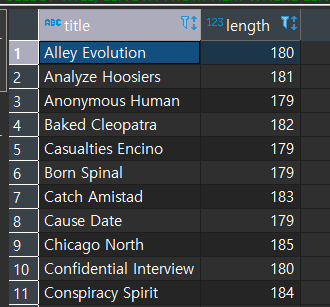
서브쿼리의 결과집합에서 상영시간의 최소값은 178이었다.
>= ANY를 통해 상영시간이 178분 이상인 모든 영화를 추출했다.
만약 =ANY를 한다면?
16개의 상영시간 집합과 같기만 하면 추출해 준다. 이것은 IN을 썼을 때와 결과가 동일하다
(=ANY와 IN은 같다)
42. 집합 연산자와 서브쿼리 - 07. ALL연산자
ALL 연산자는 값을 서브쿼리에 의해 반환된 값 집합과 비교하고,
서브쿼리의 모든 값이 만족을 해야만 조건이 성립된다.
[실습1]
방금 실습한 SQL문에서 ANY 연산자를 ALL 연산자로 바꿔본다.
SELECT TITLE, LENGTH
FROM FILM
WHERE LENGTH >= ALL (
SELECT MAX(LENGTH)
FROM FILM A, FILM_CATEGORY B
WHERE A.FILM_ID = B.FILM_ID
GROUP BY B.CATEGORY_ID
);
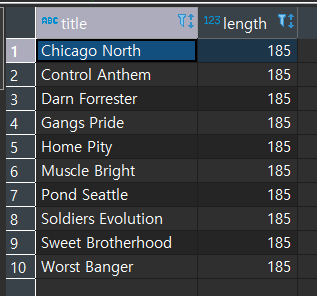
서브쿼리 결과집합에서 가장 최대값인 185 보다 큰 모든 값이 출력된다.
[실습2]
먼저 시청등급별 영화 상영시간의 평균값을 구해본다.
SELECT RATING, ROUND(AVG (LENGTH), 2)
FROM FILM
GROUP BY RATING;
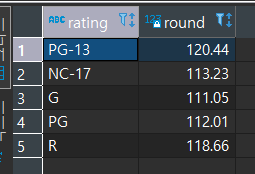
여기에 >= ALL을 적용하면, 최대값인 120.44보다 긴 상영시간의 영화들이 출력될 것이다.
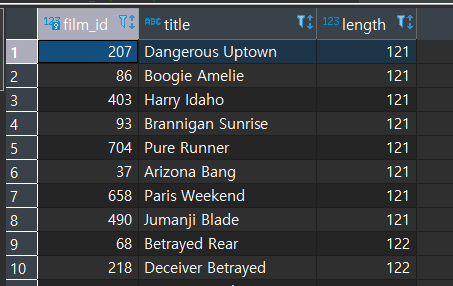
SELECT FILM_ID, TITLE, LENGTH
FROM FILM
WHERE LENGTH > ALL (
SELECT ROUND(AVG (LENGTH), 2)
FROM FILM
GROUP BY RATING
)
ORDER BY LENGTH;
43. 집합 연산자와 서브쿼리 - 08. EXISTS연산자
EXISTS 연산자는 서브쿼리 내에 집합이 존재하는지 존재 여부만을 판단한다.
존재 여부만을 판단하므로 연산시 부하가 줄어든다.
(해당 집합이 존재하기만 하면 더이상 연산을 멈추므로 성능상 유리함)
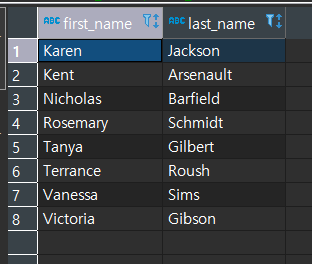
[실습1]
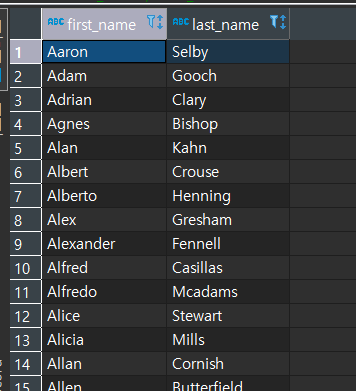
SELECT FIRST_NAME, LAST_NAME
FROM CUSTOMER C
WHERE EXISTS (
SELECT 1
FROM PAYMENT P
WHERE P.CUSTOMER_ID = C.CUSTOMER_ID
AND P.AMOUNT > 11
)
ORDER BY FIRST_NAME, LAST_NAME;
서브쿼리의 SELECT 1은 결과 집합의 갯수만큼 1로된 행을 출력한다 (결과 집합의 행의 수가 N개이면 1이 N행 반환)
여기서 1은 TRUE를 의미한다.
즉, WHERE EXISTS 조건문에 컬럼이 명시되어 있지 않기 때문에,
SELECT에도 컬럼을 명시할 필요가 없어서 임의의 값인 1을 넣은 것이다.
[실습2]
이번에는 NOT EXISTS를 사용해본다.
SELECT FIRST_NAME, LAST_NAME
FROM CUSTOMER C
WHERE NOT EXISTS (
SELECT 1
FROM PAYMENT P
WHERE P.CUSTOMER_ID = C.CUSTOMER_ID
AND P.AMOUNT > 11
)
ORDER BY FIRST_NAME, LAST_NAME;