
▶ 이전글
2021.09.28 - [데이터 분석/Ecommerce] - [선형회귀] 고객별 연간 지출액 예측하기 - 2
[선형회귀] 고객별 연간 지출액 예측하기 - 2
▶ 이전글 2021.09.28 - [데이터 분석/Ecommerce] - [선형회귀] 고객별 연간 지출액 예측하기 - 1 [선형회귀] 고객별 연간 지출액 예측하기 - 1 ▶ 강의명 ▷ [패스트캠퍼스] 파이썬을 활용한 이커머스 데
ggarden.tistory.com
▶ 강의명
▷ [패스트캠퍼스] 파이썬을 활용한 이커머스 데이터 분석
▶ 주제
▷ ch2. 고객별 연간 지출액 예측 (Linear Regression)
-- 강의 내용 --
09-1. 파이썬 Tip ①. Numpy와 Pandas
numpy array는 일반 리스트와 약간 다르다
a = [1,2,3]
b = [4,5,6]
>> 일반 리스트

>> 리스트 [1,2,3,] 이 numpy array에 감싸진다
>> 리스트들을 요소로 받을 수 있으며 대괄호가 겹쳐서 표시된다.
np.array는 일반 리스트보다 메모리 연산 시간을 단축시켜주고, 이것은 딥러닝시에 리소스 효율을 증가시킨다.
numpy.array 이외에 pandas.dataframe (2차원)과 pandas.series (1차원)도 있다.
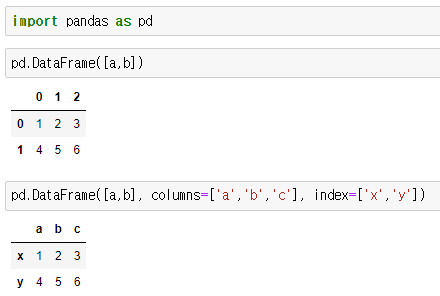
>> dataframe은 2차원 형태이며 컬럼과 인덱스를 바꿀 수도 있다.

>> series는 1차원 형태이며 일렬의 형태로 나타난다. (왼쪽은 인덱스)
type 함수를 통해 데이터 타입이 dataframe인지 series인지를 리스트 인지를 알 수 있다.

>> 앞전의 ecommerce 데이터는 dataframe이며 한 컬럼만 인덱싱하면 series로 나타난다.

>> series를 dataframe으로 변환하는 것도 가능하다
(반대는 한 컬럼만 뽑아내야 가능, series가 dataframe이 되면서 인덱스가 컬럼이 되기 때문에)
>> array를 dataframe으로 변환하는 것도 가능하다 (반대도 가능)
(하지만 이해하기 어려운 형태가 됨. 아래 사진 참조)
09-2. 파이썬 Tip ②. Pandas Indexing
dataframe의 indexing에 관해서 컬럼에 대한 부분은 앞전에서 다룬적이 있음 (drop함수)
이번에는 로우 인덱싱에 대해 알아본다.
new_data = data.head(10)
new_data.index = ['a','b','c','d','e','f','g','h','i','j']
new_data
>> data에서 10행만 뽑아 new_data로 지정하고, 인덱스를 새롭게 지정해준다. 그리고 출력하면

>> 인덱스를 숫자에서 알파벳으로 변경했다.
loc함수 (location)를 통해 인덱스명이 'd'인 행만 출력할 수 있다. (아래 사진 참조)

>> series 형태로 d행이 출력된다.
반면 iloc 함수는 integer location의 뜻으로, 정수 인덱스 값을 받는다

>> iloc[3] 의 의미는 4번째 순서인 행을 출력한다는 것을 의미한다. (loc는 인덱스 이름을 찾음)
(loc['d']와 iloc[3]은 같은 것을 알 수 있다)
** 참고로 .iloc[:] 은 전체 행을 출력한다.
로우와 컬럼을 함께 인덱싱할 수도 있다.

>> 전체 ecommerce 데이터에서 [행, 열] 순으로 로우와 컬럼을 인덱싱한다.
(new_data.iloc[:, 1:4]과 같은 응용도 가능하다)
-- 끝 --