
▶ 이전글
2021.09.28 - [데이터 분석/Ecommerce] - [선형회귀] 고객별 연간 지출액 예측하기 - 1
[선형회귀] 고객별 연간 지출액 예측하기 - 1
▶ 강의명 ▷ [패스트캠퍼스] 파이썬을 활용한 이커머스 데이터 분석 ▶ 주제 ▷ ch2. 고객별 연간 지출액 예측 (Linear Regression) -- 강의 내용 -- 01. 분석의 목적 선형회귀분석을 통해 고객체류
ggarden.tistory.com
▶ 강의명
▷ [패스트캠퍼스] 파이썬을 활용한 이커머스 데이터 분석
▶ 주제
▷ ch2. 고객별 연간 지출액 예측 (Linear Regression)
-- 강의 내용 --
06. 선형 회귀 모델 만들기
선형 회귀모델을 만들기 위해 모듈을 불러온다
import statsmodels.api as sm
model = sm.OLS(y_train, X_train)
model = model.fit()
model.summary()
>> OLS(최소제곱법)로 모델을 만든다. y값, x값임에 주의한다.
>> 만들어진 모델을 fit()으로 train을 한번 해준다.

>> summary함수를 통해 만들어진 모델의 상세내용을 확인할 수 있다.
07. 모델을 활용하여 예측하고 평가하기 ①
그리고 test set으로 모델을 검증해본다
pred = model.predict(X_test)
>> test set의 예측값을 pred 변수에 저장한다.
그리고 얼마만큼 잘 예측했는지 y_test와 비교해 본다. (scatter plot을 그릴 것이다)

plt.figure(figsize=(10,10))
sns.scatterplot(x = y_test, y = pred)
>> 10x10으로 plot의 크기를 설정하고 seaborn 모듈의 scatterplot을 그린다
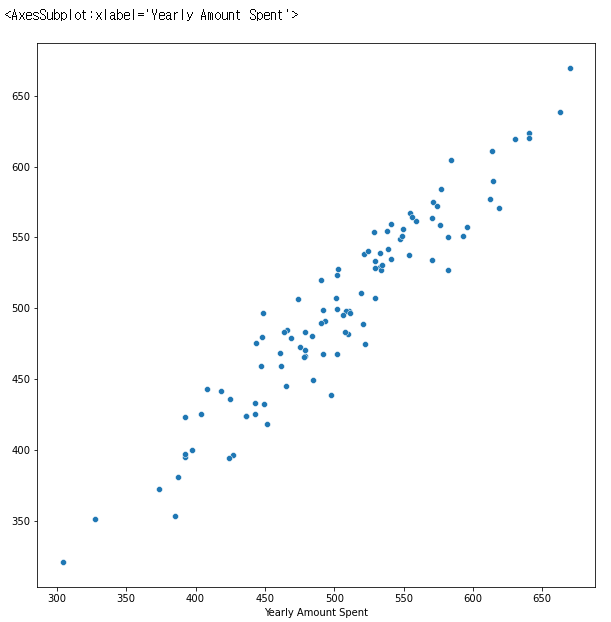
>> 양의 상관관계를 그리며 모델의 예측력이 유의미하게 높은 것을 알 수 있다.
08. 모델을 활용하여 예측하고 평가하기 ②
MSE(mean squared error) : 평균오차제곱을 이용해 모델의 신뢰성을 살펴본다.
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test, pred)
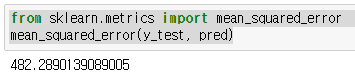
오차제곱의 평균을 계산한 것이므로 MSE는 낮을 수록 좋다.
대략 482로 관측되는데 이 MSE는 절대적인 값이 아니기 때문에 수치만 보고 좋다 나쁘다 판단이 어렵다.
또한 error를 제곱하기 때문에 1 미만의 error는 더 작아지고, 그 이상의 error는 더 커진다.
이번에는 RMSE도 살펴본다.
np.sqrt(mean_squared_error(y_test, pred))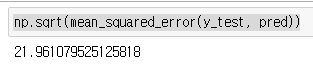
Root를 씌운 MSE는 제곱이 없어지면서 값의 왜곡을 줄이고, 수치의 괴리감을 없애, 보다 직관적으로 나타내준다.
-- 끝 --