[강의명]
패스트캠퍼스 SQL 100제 + 자격증 완성 온라인 완주반
[수강목록]
생각대로 SQL - 5
[강의내용]
생각대로 SQL - 5
문제1번) 영화배우가, 영화 180분 이상의 길이의 영화에 출연하거나, 영화의 rating이 R인 등급에 해당하는 영화에 출연한 영화 배우에 대해서, 영화배우 ID와 (180분이상 / R등급영화)에 대한 Flag 컬럼을 알려주세요.
- 1) film_actor 테이블와 film 테이블을 이용하세요.
- 2) union, unionall, intersect, except 중 상황에 맞게 사용해주세요.
- 3) actor_id가 동일한 flag 값이 여러개 나오지 않도록 해주세요.
구해야 할 컬럼이 딱 2개이다(actor_id, flag) 다만, flag의 값은 두 종류로 나와야 하기 때문에 UNION 사용을 생각해 볼 수 있다.
먼저 (1) 180분 이상 길이 영화 출연 배우를 구하고
(2) R등급 영화 출연 배우를 구한 뒤
(3) UNION으로 결합한다.
(1) 180분 이상 길이 영화 출연 배우
[내 답안]
SELECT DISTINCT fa.actor_id,
CASE WHEN f.length >= 180 THEN 'over180m'
ELSE NULL
END AS flag
FROM film_actor fa
JOIN film f ON fa.film_id = f.film_id
WHERE f.length >= 180딱 over180m의 데이터만 뽑기 위해 WHERE절에서 length >= 180의 조건을 부여한 뒤 CASE WHEN으로 flag를 달았지만, 이럴 필요 없이 새로운 컬럼을 달아줘도 된다.
[간소화된 답안]
SELECT DISTINCT fa.actor_id, 'over180m' AS flag
FROM film_actor fa
JOIN film f ON fa.film_id = f.film_id
WHERE f.length >= 180

두 방식 모두 같은 결과를 출력한다. 하지만 간소화된 쿼리를 작성하는 습관을 들이기 위해 아래의 쿼리를 사용하자
모범답안에서는 JOIN 대신 서브쿼리를 사용한다.
[모범답안]
SELECT actor_id, 'over_length180' AS flag
FROM film_actor fa
WHERE film_id IN (
SELECT film_id
FROM film f
WHERE length >= 180
)
결과에는 크게 차이가 없다. (flag의 속성값 명칭이 조금 다르다)
다만, 모범답안에서는 추후에 UNION을 사용하면서 중복값이 제거되기 때문에 현재 DISTINCT를 사용하지 않았다.
내 답안은 미리 DISTINCT를 사용했다(써도 되고 안써도 된다)
DISTINCT를 써서 출력 데이터의 크기를 줄이는 것이 좋은지 VS DISTINCT를 지우고 쿼리 자체를 최소화하는 것이 좋은지 알아보아야겠다.
(2) R등급 영화 출연 배우
[내 답안]
SELECT DISTINCT fa.actor_id, 'R' AS flag
FROM film_actor fa
JOIN film f ON fa.film_id = f.film_id
WHERE f.rating = 'R'
[모범 답안]
SELECT actor_id, 'rating_R' AS flag
FROM film_actor fa
WHERE film_id IN (
SELECT film_id
FROM film f
WHERE rating = 'R'
)
DISTINCT 사용 여부로 인해 중복값의 유무에 차이가 발생한다.
그러나 UNION 과정에서 모범답안의 중복값 문제는 해결된다.
(3) UNION으로 결합
[내 답안]
SELECT DISTINCT fa.actor_id, 'over180m' AS flag
FROM film_actor fa
JOIN film f ON fa.film_id = f.film_id
WHERE f.length >= 180
UNION
SELECT DISTINCT fa.actor_id, 'R' AS flag
FROM film_actor fa
JOIN film f ON fa.film_id = f.film_id
WHERE f.rating = 'R';
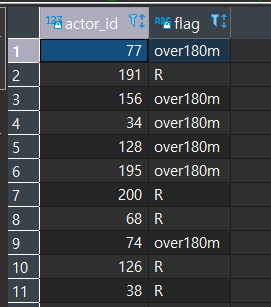
[모범답안]
SELECT actor_id, 'over_length180' AS flag
FROM film_actor fa
WHERE film_id IN (
SELECT film_id
FROM film f
WHERE length >= 180
)
UNION
SELECT actor_id, 'rating_R' AS flag
FROM film_actor fa
WHERE film_id IN (
SELECT film_id
FROM film f
WHERE rating = 'R'
);
결과는 동일하다.
UNION 과정에서 자동으로 중복값이 제거되므로 굳이 DISTINCT를 사용하지 않아도 된다.
(DISTINCT를 쓰나 안쓰나 UNION 이후 동일해짐)
문제4번) 필름 중에서, 필름 카테고리가 Action, Animation, Horror 에 해당하지 않는 필름 아이디를 알려주세요.
- category 테이블을 이용해서 알려주세요.
film_id와 함께 카테고리명도 같이 출력해본다.
[간편한 방법]
SELECT f.film_id, c.name
FROM film f
JOIN film_category fc ON f.film_id = fc.film_id
JOIN category c ON fc.category_id = c.category_id
WHERE c.name NOT IN ('Action', 'Animation', 'Horror');
[EXCEPT 사용]
SELECT f.film_id, c.name
FROM film f
JOIN film_category fc ON f.film_id = fc.film_id
JOIN category c ON fc.category_id = c.category_id
EXCEPT
SELECT f.film_id, c.name
FROM film f
JOIN film_category fc ON f.film_id = fc.film_id
JOIN category c ON fc.category_id = c.category_id
WHERE c.name IN ('Action', 'Animation', 'Horror');
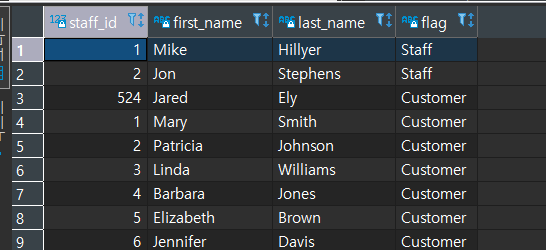
문제5번) Staff의 id, 이름, 성에 대한 데이터와, Customer의 id, 이름, 성에 대한 데이터를 하나의 데이터셋의 형태로 보여주세요.
- 컬럼 구성 : id, 이름, 성, flag (직원/고객여부)로 구성해주세요.
중복값이 출력되어도 상관없기 때문에 UNION ALL을 사용했다.
SELECT s.staff_id, s.first_name, s.last_name, 'Staff' AS flag
FROM staff s
UNION ALL
SELECT c.customer_id, c.first_name, c.last_name, 'Customer' AS flag
FROM customer c;
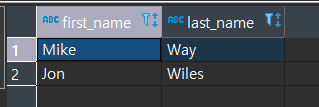
문제6번) 직원과 고객의 이름이 동일한 사람이 혹시 있나요? 있다면, 해당 사람의 이름과 성을 알려주세요.
직원과 고객의 이름이 동일? -> INTERSECT를 사용하면 된다.
SELECT first_name, last_name
FROM customer
WHERE first_name IN (
SELECT s.first_name
FROM staff s
INTERSECT
SELECT c.first_name
FROM customer c
);
문제8번) 국가(country)별 도시(city)별 매출액, 국가(country)매출액 소계 그리고 전체 매출액을 구하세요. (union all)
문제에서 요구하는 것은 3가지. 나눠서 살펴본다.
(1) 국가(country)별 도시(city)별 매출액
국가별 도시별 -> GROUP BY country, city 해주면 된다.
country 컬럼을 사용해야 하므로 많은 테이블을 JOIN해줘야 하고, amount(매출액)를 구하기 위해 payment 테이블을 가가져온다.
SELECT country, city, sum(amount)
FROM (
SELECT co.country, ci.city, p.amount
FROM payment p
JOIN customer c ON p.customer_id = c.customer_id
JOIN address a ON c.address_id = a.address_id
JOIN city ci ON a.city_id = ci.city_id
JOIN country co ON ci.country_id = co.country_id
) db
GROUP BY country, city

(2) 국가(country) 매출액 소계
위에서 작성한 쿼리에서 city를 제거해주면 된다.
SELECT country, sum(amount)
FROM (
SELECT co.country, ci.city, p.amount
FROM payment p
JOIN customer c ON p.customer_id = c.customer_id
JOIN address a ON c.address_id = a.address_id
JOIN city ci ON a.city_id = ci.city_id
JOIN country co ON ci.country_id = co.country_id
) db
GROUP BY country

(3) 전체 매출액
위에서 작성한 쿼리에서 country, city를 제거하고 sum(amount)만 SELECT해주면 된다.
SELECT sum(amount)
FROM (
SELECT co.country, ci.city, p.amount
FROM payment p
JOIN customer c ON p.customer_id = c.customer_id
JOIN address a ON c.address_id = a.address_id
JOIN city ci ON a.city_id = ci.city_id
JOIN country co ON ci.country_id = co.country_id
) db;

이제 (1)~(3)을 전부 UNION ALL 해준다.
바로 UNION ALL을 시행하면 에러가 발생한다. 컬럼의 갯수가 다르기 때문이다.
방금 구한 전체매출액의 경우 1X1이기 때문에 이를 3X1로 만들려면 SELECT시, NULL을 추가해 준다.
SELECT country, city, sum(amount)
FROM (
SELECT co.country, ci.city, p.amount
FROM payment p
JOIN customer c ON p.customer_id = c.customer_id
JOIN address a ON c.address_id = a.address_id
JOIN city ci ON a.city_id = ci.city_id
JOIN country co ON ci.country_id = co.country_id
) db
GROUP BY country, city
UNION ALL
SELECT country, NULL, sum(amount)
FROM (
SELECT co.country, ci.city, p.amount
FROM payment p
JOIN customer c ON p.customer_id = c.customer_id
JOIN address a ON c.address_id = a.address_id
JOIN city ci ON a.city_id = ci.city_id
JOIN country co ON ci.country_id = co.country_id
) db
GROUP BY country
UNION ALL
SELECT NULL, NULL, sum(amount)
FROM (
SELECT co.country, ci.city, p.amount
FROM payment p
JOIN customer c ON p.customer_id = c.customer_id
JOIN address a ON c.address_id = a.address_id
JOIN city ci ON a.city_id = ci.city_id
JOIN country co ON ci.country_id = co.country_id
) db;
끝.